서론
주어진 데이터에 대해 머신 러닝 모델을 만들고 학습시키기 위해서는 우선 데이터를 분리할 필요가 있다.
데이터를 분리하지 않고 학습과 평가에 모두 사용하는 것은, 마치 중간 고사 문제를 미리 풀고 시험을 보는 것과 같다.
그런 식으로 평가한다면, 모델의 정확도는 분명 높을 것이고, 평가에 대한 객관성도 떨어진다.
또한 이렇게 만들어진 모델은 주어진 데이터데 대한 '과적합 (Overfitting)' 판단이 어려울 수 있다.
따라서 모델을 생성하기 전,
주어진 데이터를 학습할 데이터와 (trining set) 평가할 데이터로 (test set) 분리해야한다.
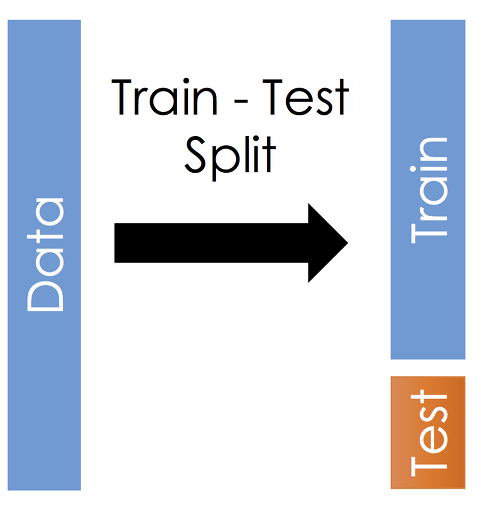
본론
사이킷런 라이브러리에는 훈련 데이터와 학습 데이터를 분리해주는 함수가 있다.
<sklearn.model_selection.train_test_split>
이 함수를 이용하면 원본 데이터를 알아서 훈련 세트와 테스트 세트로 나눠주므로 굉장히 편리하다.
함수를 이용하기 전 중요한 매개 변수는 미리 알아둘 필요가 있다.
train_test_split(X, y, test_size, train_size, random_state, shuffle, stratify)
- X : 특성 데이터
- y : 클래스, 레이블
- test_size : 평가 셋의 비율을 정해주는 매개 변수, default = 0.25
- train_size : 훈련 셋의 비율을 정해주는 매개 변수, 1 - test_size = train_size
- random_state : 랜덤 시드를 정해주는 매개 변수
- shuffle : 데이터를 분리하기 전 섞을지 정하는 매개 변수, boolean
- stratify : 훈련셋과 평가셋을 나눌 때 결과 y의 비율을 맞춰 나눌지 정하는 변수, boolean
- 반환값
( X_train, X_test, y_train, y_test ) : 훈련 데이터. 테스트 데이터, 훈련 레이블, 테스트 레이블 순서의 tuple로 반환
( X_train, X_test ) : 레이블(y) 없이 데이터만 넣었을 경우의 반환 형식, 데이터만 분리되어 tuple로 반환
이 함수의 용도와 입력값 (주요 매개 변수), 반환값을 이해했다면, 즉시 불러와 사용할 수 있다.
실제 데이터를 이용해 이 함수를 어떻게 사용하고 어떤 결과 가져오는지 확인해보자.
사이킷런에서 제공하는 붓꽃 데이터를 위 함수를 이용해 훈련 세트와 테스트 세트로 분리해보겠다.
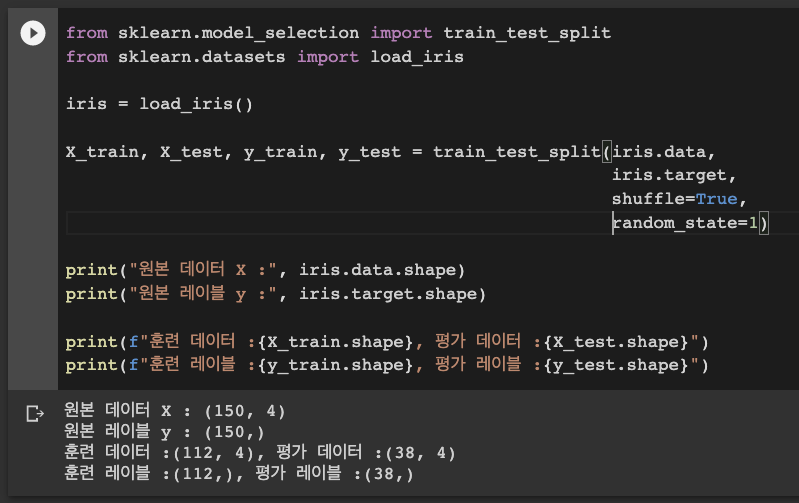
함수의 이용 방법을 간단히 서술하자면,
tuple 형태로 반환되는 반환값을 각각 입력받을 변수에 할당한다. 이 때 변수의 순서는 매우 중요하다.
(X_train, X_test, y_train, y_test)
<train_test_split> 함수를 원하는 매개 변수를 입력해 실행시킨다.
분리가 정상적으로 진행되었는지 확인해 보았다.
원본 붓꽃 데이터는 4개의 특성을 가진 총 150개의 붓꽃 데이터를 가지고 있다. ( 원본 데이터 )
마찬 가지로 원본 레이블은 총 150개가 확인된다. ( 원본 레이블 )
<train_trest_split> 함수를 사용해 데이터와 레이블을 훈련 세트, 테스트 세트 각각 112개와 38개로 분리하였다.
(훈련 데이터/레이블, 평가 데이터/레이블)
응용
원본 데이터의 분리의 근본적인 목적은 머신러닝 모델의 학습과 테스트를 위한 것이다.
임의의 머신러닝 모델을 생성하고 훈련 데이터/레이블로 학습한 후,
모델이 평가 데이터 예측을 진행해보면 아래와 같은 결과를 확인할 수 있다.
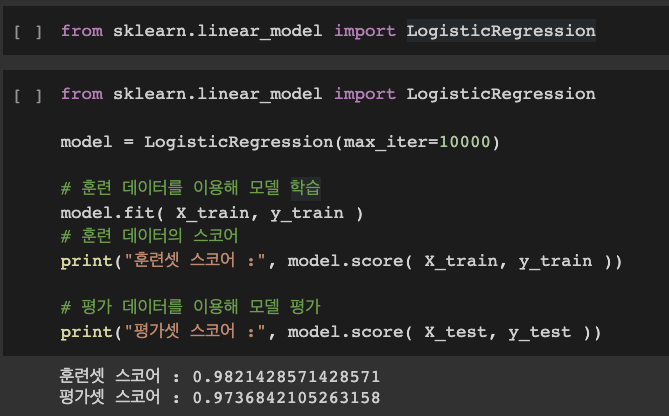
여기서 스코어란 정확도를 (Accuracy) 표시한 것으로,
모델이 데이터로 예측한 값이 실제 레이블과 얼마나 일치하는지를 확인할 수 있다.
일반적으로 모델의 훈련 데이터에 대한 정확도가 평가 데이터에 대한 정확도 보다 높다.
기출문제로 공부한 학생이 같은 기출 문제를 다시 보는가, 혹은 새로운 시험을 치르는가의 차이라고 이해하면 쉽다.
단순히 데이터를 나눠주는 것만으로도 모델의 정확도에 객관성을 부여할 수 있다.
이후 포스팅에서는 한정된 학습 데이터를 이용해, 모델의 정확도에 좀 더 객관성을 줄 수 있는 방법을 알아보자.
'파이썬도르 > 머신러닝' 카테고리의 다른 글
| 교차 검증 (Cross Validation) <sklearn.model_selection.cross_validate> (0) | 2021.04.22 |
|---|