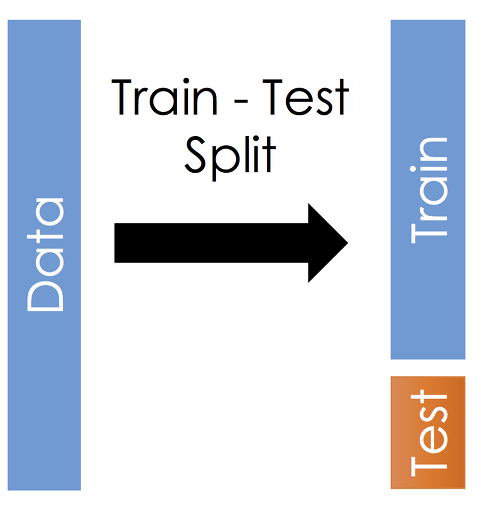
지난 글에서 분류형 데이터 (Categorical Data) 특성 별로 시각화하여 살펴보았습니다. 전반적으로 데이터 불균형이 확인되었으며, 희소한 데이터도 많아 모델 생성 및 학습 전 이를 해결해야할 것 같습니다. 분류형 데이터의 EDA 및 시각화 01_ 탐색적 데이터 분석 (EDA) - 데이터 시각화 (1) 탐색적 데이터 분석 (Exploratory Data Analysis) 이란 본격적인 모델링을 시작하기 전, 데이터에 대한 인사이트를 얻기 위해 데이터의 종류 및 분포 등을 확인하는 작업입니다. 이 과정을 거침으로서 zngsup.tistory.com 이번 포스팅에서는 수치형 데이터를 (Numeric Data) 시각화해 데이터의 특성을 시각화로 확인합니다. 분류형 데이터와는 다르게 수치형 데이터는 '연..