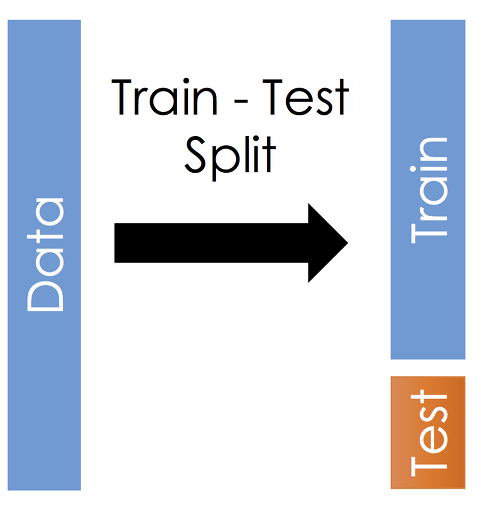
서론주어진 데이터에 대해 머신 러닝 모델을 만들고 학습시키기 위해서는 우선 데이터를 분리할 필요가 있다. 데이터를 분리하지 않고 학습과 평가에 모두 사용하는 것은, 마치 중간 고사 문제를 미리 풀고 시험을 보는 것과 같다.그런 식으로 평가한다면, 모델의 정확도는 분명 높을 것이고, 평가에 대한 객관성도 떨어진다. 또한 이렇게 만들어진 모델은 주어진 데이터데 대한 '과적합 (Overfitting)' 판단이 어려울 수 있다. 따라서 모델을 생성하기 전,주어진 데이터를 학습할 데이터와 (trining set) 평가할 데이터로 (test set) 분리해야한다. 본론사이킷런 라이브러리에는 훈련 데이터와 학습 데이터를 분리해주는 함수가 있다. 이 함수를 이용하면 원본 데이터를 알아서 훈련 세트와 테스트 세트로 나눠..